Disaster Response Pipeline Project
Introduction
During disaster events, sending messages to appropriate disaster relief agencies on a timely manner is critical. Using natural language processing and machine learning, I built a model for an API that classifies disaster messages and also a webapp for emergency works.
- First, I developed an ETL pipeline that can:
- Loads the messages and categories datasets
- Merges the two datasets
- Cleans the data
- Stores it in a SQLite database
- Then, I created a machine learning pipeline that can:
- Loads data from the SQLite database
- Splits the dataset into training and test sets
- Builds a text processing and machine learning pipeline
- Trains and tunes a model using GridSearchCV
- Outputs results on the test set
- Exports the final model as a pickle file
- Finally, A WEB APP where an emergency worker can input a new message and get classification results in several categories was developed. The web app also displays visualizations of the data.
Installation
The code was developed using the Anaconda distribution of Python, versions 3.8.1. Python libraries used are numpy, pandas, sqlalchemy, plotly, sklearn, nltk, pickle, utility, flask, wordcloud
File Descriptions
In the Project Workspace, you’ll find a data set containing real messages that were sent during disaster events.
apptemplatesmaster.html- main page of web appgo.html- classification result page of web app
utility.py- customized transformers and functionsrun.py- Flask file that runs app
datadisaster_categories.csv- data to processdisaster_messages.csv- data to processETL_Pipeline_Preparation.ipynb- notebook to explore the datasets and prepare ETL pipelineprocess_data.py- ETL pipeline to clean and store data into a SQLite databaseDisasterResponse.db- database to save clean data to
modelstrain_classifier.py- Use ML pipeline to train and save the trained model in a pickle fileclassifier.pkl- saved modelML_Pipeline_Preparation.ipynb- notebook to try ML models and prepare ML pipelineutility.py- customized transformers and functions
README.md
Instructions:
-
Run the following commands in the project’s root directory to set up your database and model.
-
To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db -
To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl
-
-
Run the following command in the app’s directory to run your web app.
python run.py -
Go to http://0.0.0.0:3001/
-
The webapp files are in the webapp branch
The web app is at webapp homepage
Screenshots
1. Home Page
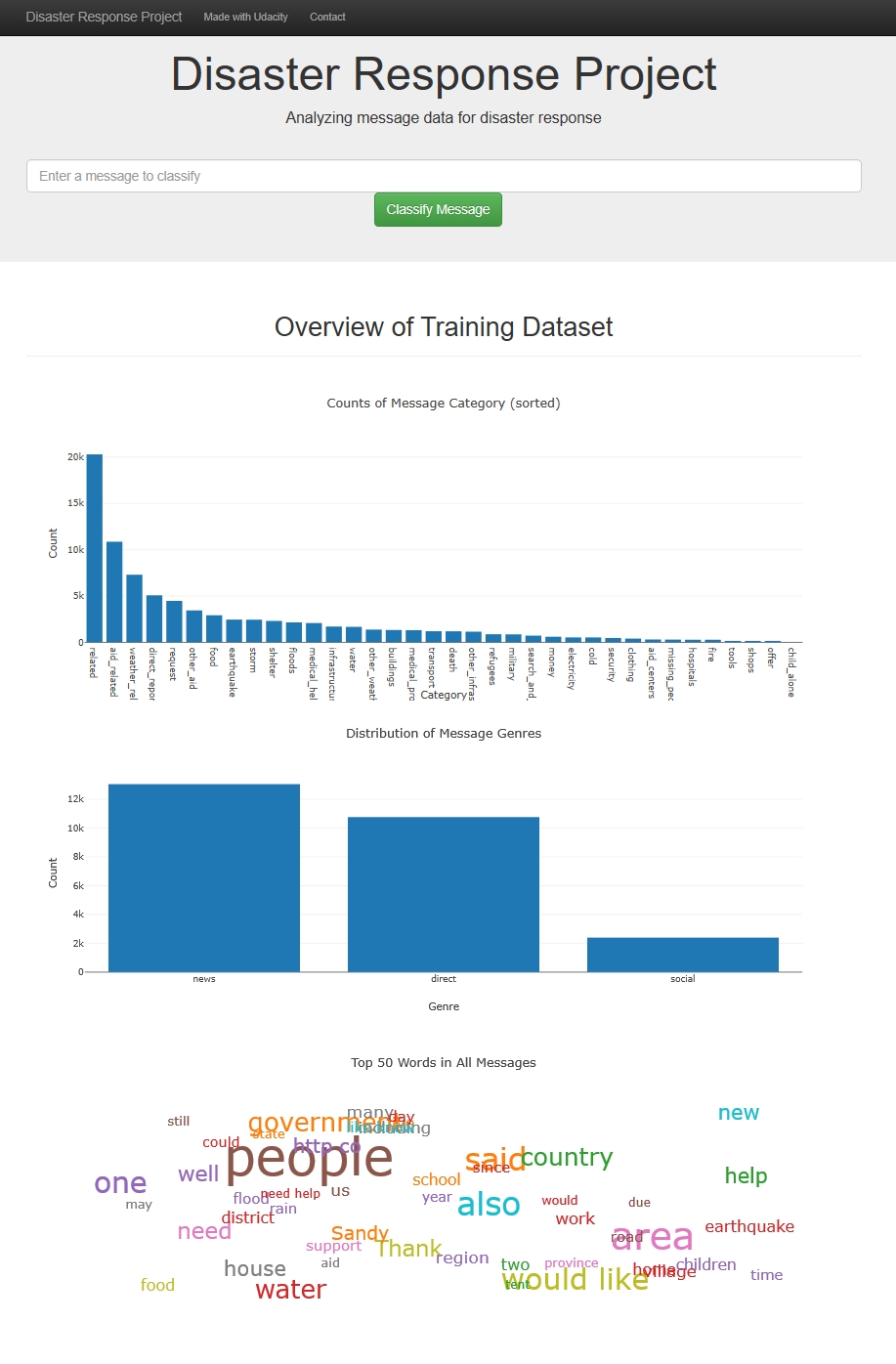
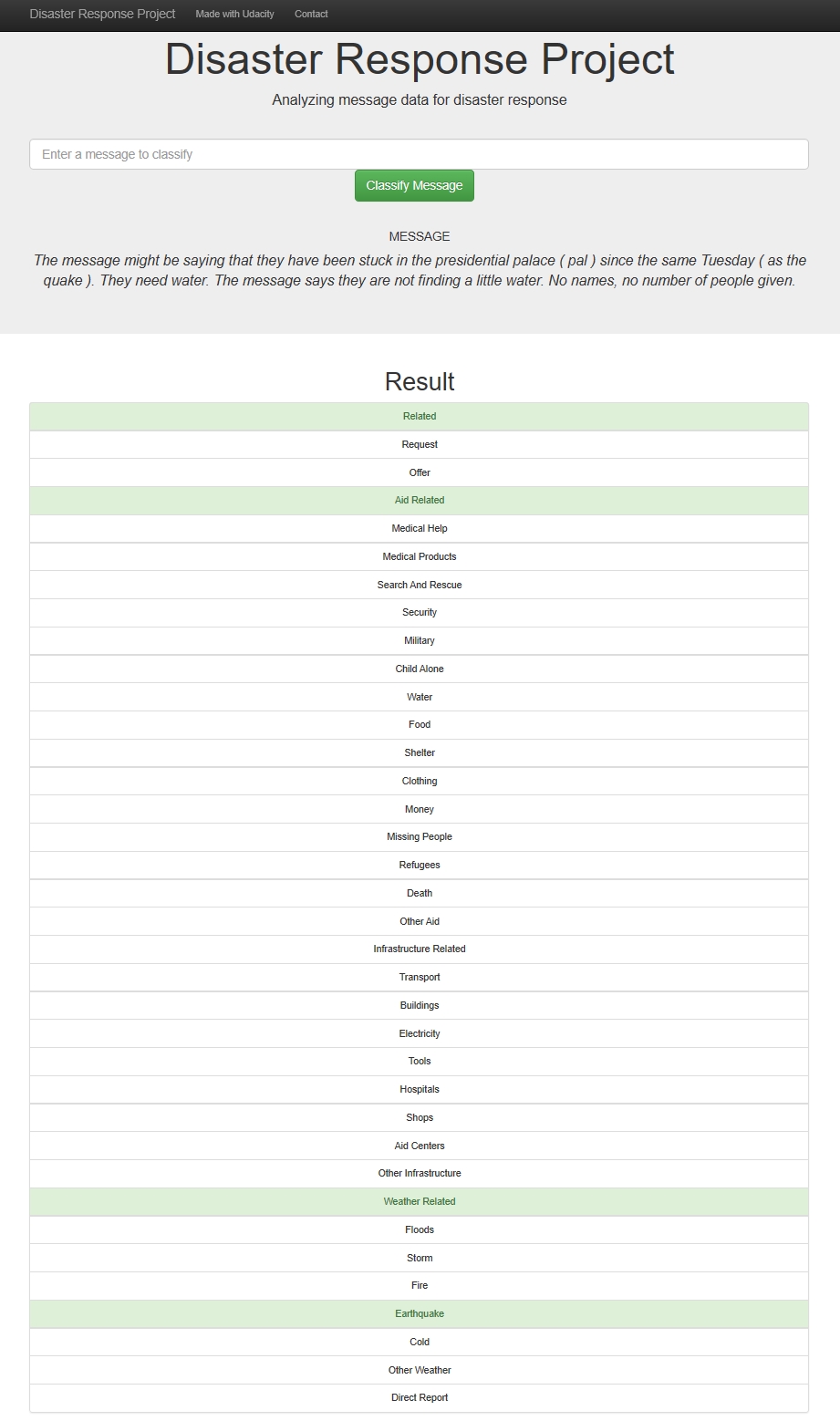
2. Message Categories
Acknowledgements
Special thanks to Figure Eight for providing the dataset.